What is GYSTC?
GYSTC is a local memory daemon for Claude. It indexes your Obsidian vault (or any
folder of markdown files), builds a semantic search index, and exposes MCP tools
that let Claude retrieve, store, and connect knowledge across sessions.
No cloud. No accounts. Clients talk plain MCP over stdio; behind that, one shared
daemon on 127.0.0.1 serves them all — the embedding model loads once, not once per
window. Never phones home.
Requirements
- Windows 10+ or macOS 12+
- Claude Desktop or Claude Code (CLI)
- An Obsidian vault (or any folder with .md files)
Installation
Download the EXE (Windows) or .app (macOS) from the release page. Run it.
The setup wizard walks you through pointing at your vault and registering the
MCP server with Claude.
That's it. Next time you open Claude, it has memory.
What Claude gets
brain_retrieve — hybrid search + file context + graph traversal (absorbed brain_context)brain_store — save new knowledge as a notebrain_recent — see recently modified notesbrain_related — find connected topics via backlinks + embeddingsbrain_classify — classify, reclassify, or teach the classifier (merged 3 tools)brain_versions — history, diff, and rollback in one tool (merged 3 tools)brain_regions — list all 12 regions with statsbrain_status — vault health check
How it organizes knowledge
Notes are classified into 12 brain regions by function, not topic. Architecture
decisions go to the Prefrontal Cortex. API endpoints go to Motor Cortex. Config
files go to Brainstem. When Claude searches, it targets the relevant regions first
— not a flat sweep of everything.
Session auto-context
A SessionStart hook fires every time you open Claude. It reads your
current git context and pulls relevant vault notes automatically. Claude starts
every session already knowing what you're working on.
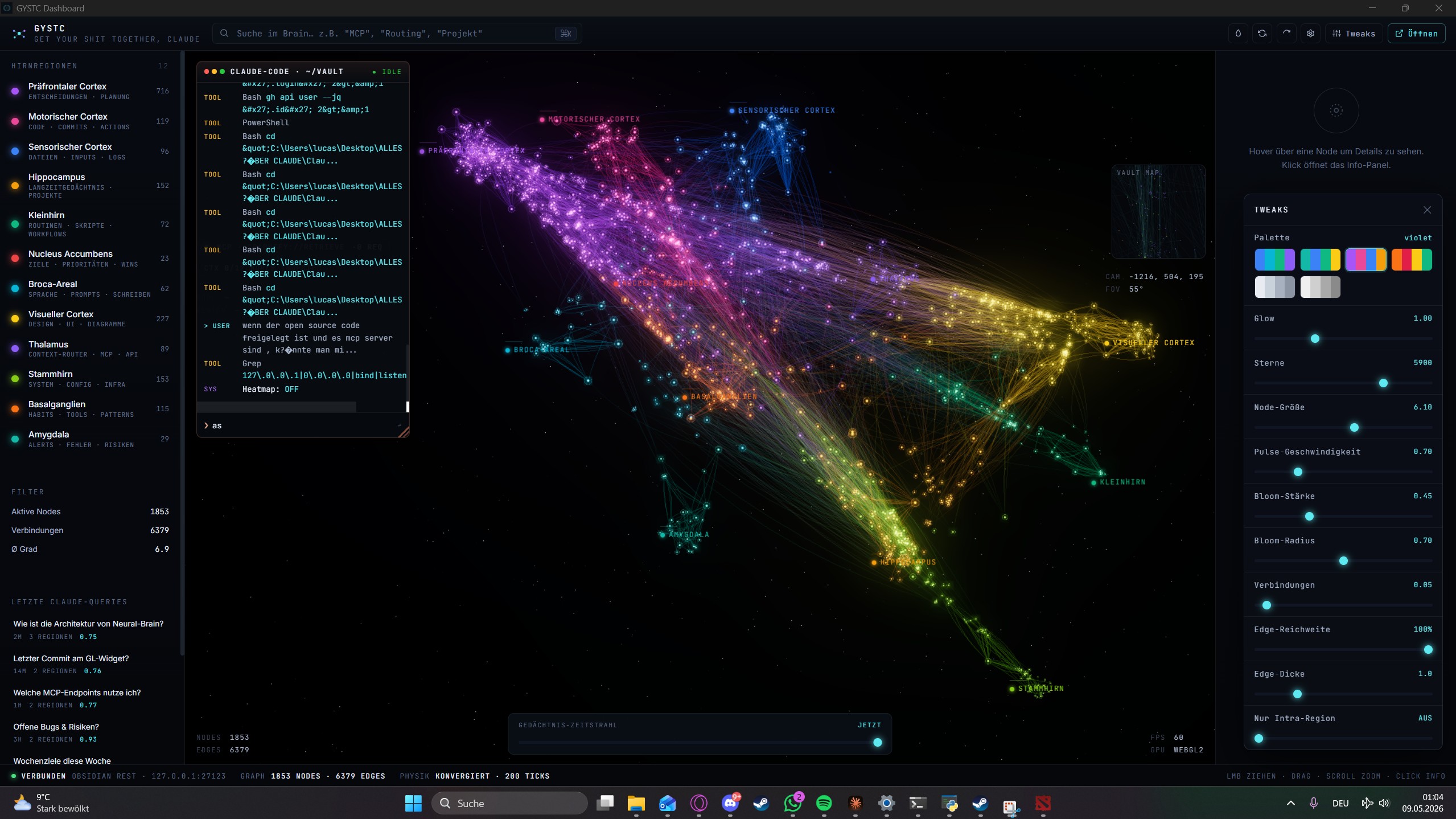
Dashboard
The EXE includes a 3D brain visualization built with Three.js. Your vault rendered
as a force-directed graph — nodes are notes, edges are backlinks, colors are regions.
Click any node to open the note in Obsidian.
Source code
Everything is free — the binary and the full source. The code is public on
GitHub:
read it, build it, self-host it. No paywall. If GYSTC saves you time and you want to
support development, there's an optional Patreon — but the code is yours either way.